JMX stands for Java Management Extension, it was introduced as part Java Enterprise Edition (JEE) and later has become an integral part of JVM.
JVM exposes a handful of useful information on diagnostic tooling through the JMX interface.
Many popular tools such as Visual VM and Mission Control are heavily based on JXM. Event Java Flight Record is exposed for remote connection via JMX.
Middleware and libraries are also exploiting JMX to expose custom MBeans with helpful information.
So if you are in the business of JVM monitoring or diagnostic tooling you cannot avoid dealing with JMX.
JMX is a remote access protocol, it is using TCP sockets and requires some upfront configuration for JVM to start listening for network connections (though tools such as VisualVM can enable JMX at runtime, provided they have access to the JVM process).
You can find details about JMX agent configuration in official documentation, but below is minimal configuration (add snippet below to JVM start command).
-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port=55555
JVM will start listening on port 5555. You would be able to use this port in Visual VM and other tools.
Configuration above is minimal, access control and TLS encryption are disabled. You should consult documentation mentioned above to add security (which would be typically required in a real environment).
JMX is a capable protocol, but it has some idiosyncrasies due to its JEE lineage. In particular, it has specific requirements for network topology.
JVM is based on Java RMI protocol. Access to JMX agent has a two step handshake.
On the first step, the client makes a request to the RMI registry and receives a serialized remote interface stub. JXM agent has a built-in single object registry which is exposed on port 5555 in our example.
On the second step, client to accessing remote interface via network address embedded in this stub object received on the first step.
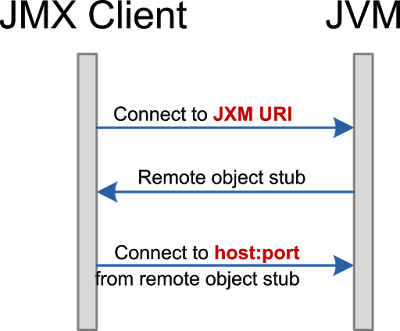
In a trivial network, this is not an issue, but if there are any form of NAT or proxy between JMX client and JVM things are likely to break.
So we have two issues here:
1. Stub could be exposed on different port number, which is not whitelisted
2. Stub may provide some kind of internal IP, not routable for client host
First issue is easily solvable with com.sun.management.jmxremote.rmi.port property, which can be set to the same value as registry port (5555 in our example).
Second issue is much more tricky as JVM may be totally unaware of IP visible from outside, even worse such IP could be dynamic so it cannot be configured via JVM command line.
In this article, I would describe a few recipes for dealing with JMX in the modern container/cloud world. None of them is ideal, but I hope at least one could be useful for you.
Configuring JMX for known external IP address
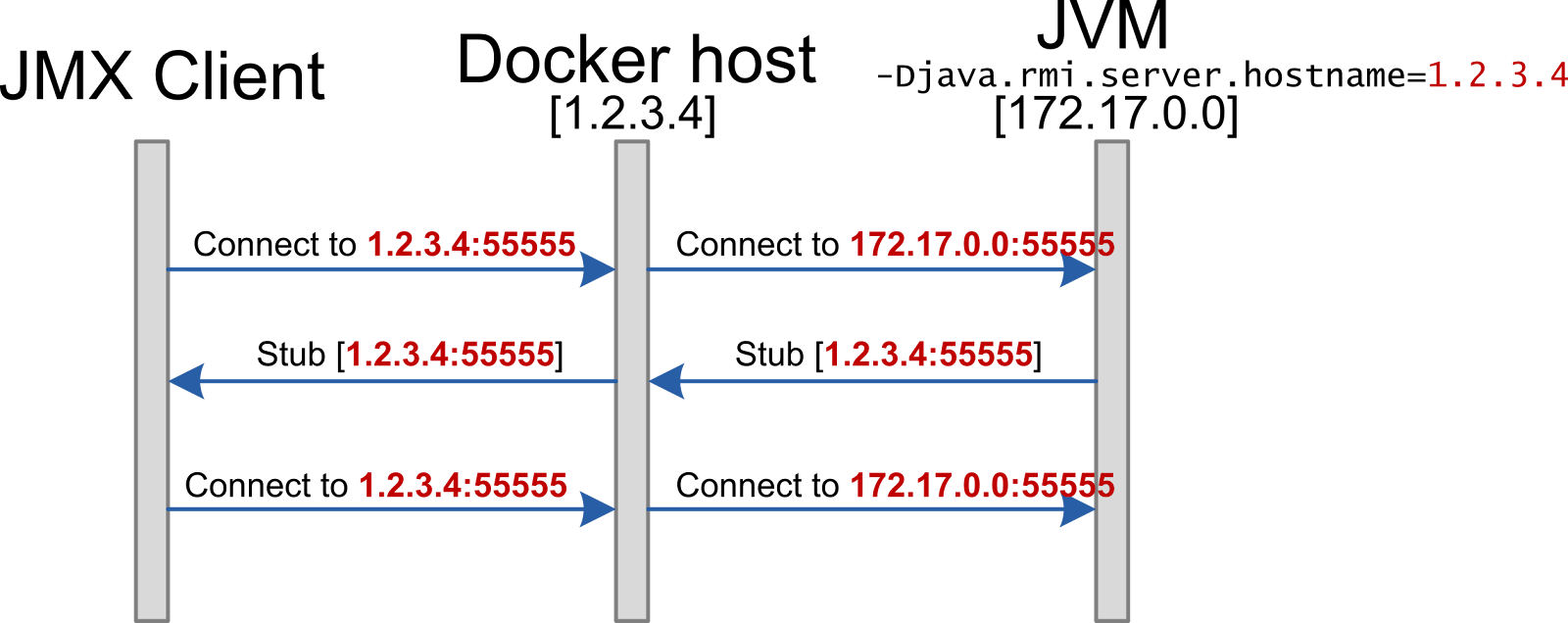
In case if you know a routable IP address, the solution is to configure the JVM to provide specific IP inside of the remote interface stub. Example for this situation would be running a JVM in a local Docker container.
JVM parameter -Djava.rmi.server.hostname=<MyHost> can be used to override IP in remote stubs provided by JMX agent. This parameter affects all RMI communication, but RMI is rarely used nowadays besides the JXM protocol.
Resulting communication scheme is outlined on the diagram below.
|
JVM options |
|
-Djava.rmi.server.hostname=1.2.3.4 |
|
Communication diagram |
|
|
Configuring JMX for tunneling
In some situations, the IP address of the JVM host may not be even reachable from the JMX client host. Here is a couple of typical examples
● You are using SSH to access the internal network through a bastion host.
● JVM is in Kubernetes POD.
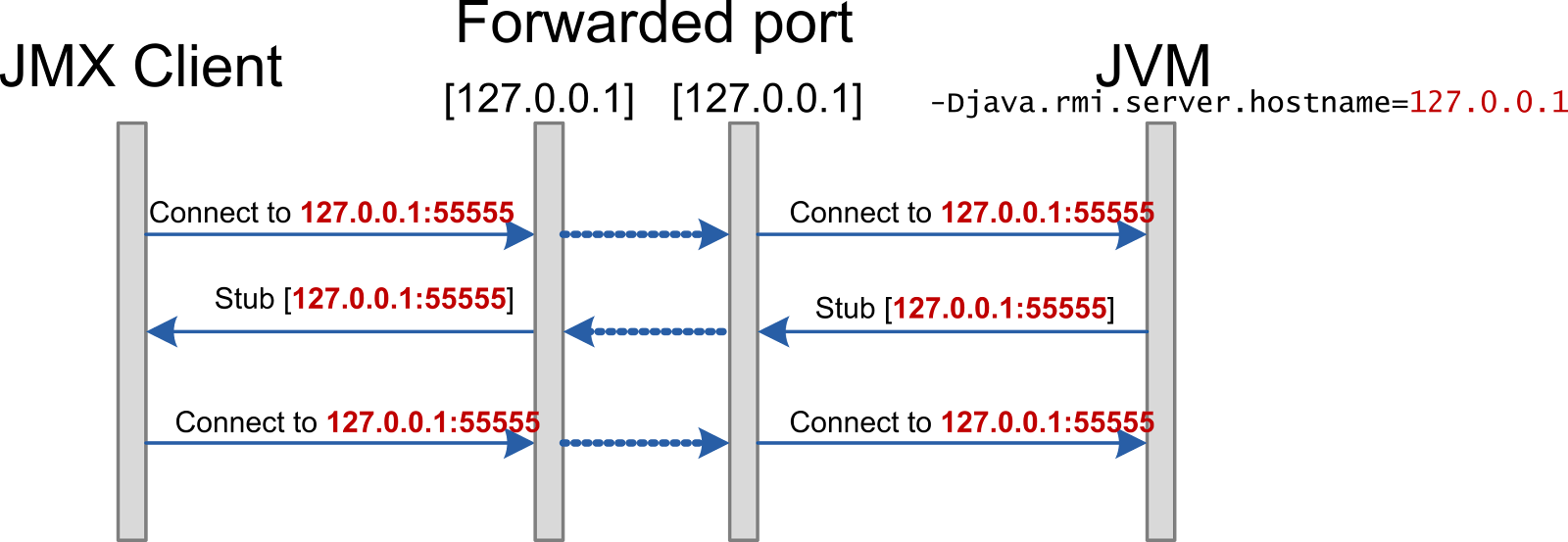
In both situations you can use port forwarding to establish a network connectivity between JMX client and JVM.
Again, you would need to override IP in remote service stub, but now you will have to set it to 127.0.0.1.
Communication diagram is shown below.
|
JVM options |
|
-Djava.rmi.server.hostname=127.0.0.1 |
|
Communication diagram |
|
|
In the case of SSH, you
can use port forwarding.
In Kubernetes, there is also a handy kubectl port-forward command which allows
to communicate with POD directly.
You can even chain port-forwarding multiple times.
Though this approach has its own limitations.
● JMX will not be available for remote hosts without port forwarding any more, so this configuration may interfere with monitoring agents running in your cluster and collecting JMX metrics.
● You cannot connect to multiple JVMs using the same JMX port (e.g. PODs from single deployment), as your port on client host is bound to a particular remote destination. Remapping ports will break the JMX.
Using HTTP JMX connector
Root of the problem is the RMI protocol which is archaic and doesn’t evolve to support modem network topologies. JMX is flexible enough to use alternative transport layers and one of them is HTTP (using Jolokia open source project).
Though implementation doesn’t come out of the box. You will have to ship a Jolokia agent jar with your application and introduce it via JVM command like Java agent (see details here).
Good news is that nowadays tools such as VisualVM and Mission Control fully support Jolokia JMX transport. Below are few demo videos for Jolokia project:
● Connect Visual VM to a JVM running in Kubernetes using Jolokia
● Connect Java Mission Control to a JVM in Kubernetes
In addition to classic tools, Jolokia HTTP endpoint is accessible from client side JavaScript so web client is also possible. See Hawt.IO project implement diagnostic web console for Java on top of Jolokia.
Using SJK JMX proxy
Dealing with JMX over the years, at some point I have decided to make a diagnostic tool specifically for JMX connectivity troubleshooting.
It is part of SJK - my jack-of-all-knives solution for dealing with JVM diagnostics. mxping command can help to identify, which part of JMX handshake is broken.
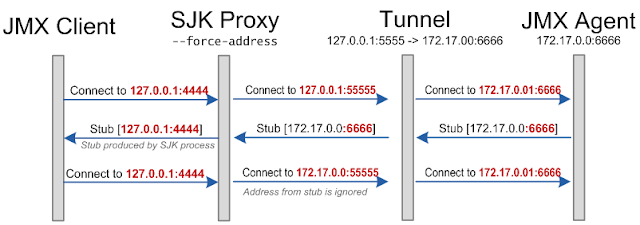
While implementing mxping, I have realized that I can solve the root cause of RMI network sensitivity by messing with JMX client code. As I am not eager to patch all JMX tools around, I have introduced JMX Proxy (mxprx), which can be used between JMX Client and remote JVM.
Using JMX proxy may eliminate issues with port forwarding scenario mention above as
● It does require -Djava.rmi.server.hostname=127.0.0.1 on the JVM side.
● Allow you remap ports and thus keep multiple ports forwarded at the same time.
Below is a communication diagram using JMX proxy from SJK.
In addition, with JMX proxy ad hoc configuration of JMX endpoint without JVM restart becomes possible.
JMX agent could be started and configured at runtime via jcmd, but java.rmi.server.hostname can only be set in the command line of the JVM. But with JMX proxy we do not rely on java.rmi.server.hostname anymore!
Below are steps to connect to the JVM in the Kubernetes POD even if JMX was not configured upfront.
1. Enter the container shell using the kubectl exec command.
2. In the container, use jcmd ManagementAgent.start to start JMX agent (see more details here).
3. Forward port from container to your local host.
4. Start JMX proxy on your host pointing it on localhost:<port forwarded from container> and provide some outbound port (see more details here).
5. Now you can connect with any JMX aware tool via locally running JMX proxy.
Conclusion
I have listed four alternative approaches for JMX setup. None of them are universal unfortunately and you have to pick one which is most suitable for your case.
While JMX is kind of archaic it is still essential for JVM monitoring and you are likely to have to deal with it for any serious Java based system.
I hope someday HTTP will become built-in and default for JVM and all this trickery will become a horror story from the old days.










